
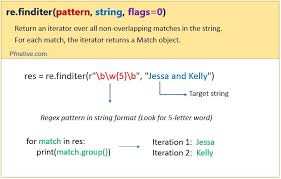
Regular expressions, commonly referred to as regex, are powerful tools used in computing for pattern matching within strings of text. They provide a concise and flexible means of searching, extracting, and manipulating text based on specific patterns or rules defined by the user.
One of the key advantages of using regex is its versatility in handling complex search patterns. Whether you need to find specific words, characters, or sequences within a text document, regex offers a robust solution that can be customised to suit your needs. This flexibility makes it an invaluable tool for tasks such as data validation, text processing, and search operations.
In addition to its versatility, regex is supported by a wide range of programming languages and tools, making it a portable solution that can be implemented across different platforms. From Python to JavaScript, PHP to Java, regex syntax is consistent across various programming environments, allowing developers to leverage its power regardless of the language they are working with.
Despite its many benefits, mastering regex can be challenging due to its cryptic syntax and intricate rules. Beginners may find themselves grappling with complex expressions and debugging errors that arise from incorrect pattern definitions. However, with practice and patience, developers can unlock the full potential of regex and harness its capabilities to streamline their coding tasks.
In conclusion, regex is a valuable tool for anyone working with text data in computing. Its ability to handle intricate search patterns with precision and efficiency makes it an indispensable asset in tasks ranging from data parsing to web scraping. By understanding the principles behind regex and investing time in learning its syntax, developers can enhance their coding skills and improve their efficiency when working with textual data.
Understanding Regex in R: Special Characters and Their Uses
- What is \r and \n in regex?
- What is the use of \\ in R?
- Why is \\ used in regex?
- What is the R in regex?
What is \r and \n in regex?
In regex, the symbols \r and \n represent special characters that are used to denote specific types of line breaks. The \r character stands for a carriage return, which is a control character that moves the cursor to the beginning of the current line without advancing to the next line. On the other hand, the \n character represents a newline, which signifies the end of a line and moves the cursor to the beginning of the next line. Understanding how to use \r and \n in regex is crucial for manipulating text data and formatting strings effectively, especially when dealing with tasks that involve processing or extracting information from multi-line text documents.
What is the use of \\ in R?
In the context of regex in R, the use of double backslashes (\\) serves a specific purpose in defining escape characters. In R, backslashes are considered escape characters that modify the interpretation of subsequent characters. By using double backslashes, users can specify literal backslashes within regex patterns to ensure that they are treated as regular characters rather than escape sequences. This is particularly useful when dealing with special characters or metacharacters in regex patterns, allowing for precise matching based on the desired text structure without unintended interpretations. Understanding the significance of double backslashes in R regex is essential for crafting accurate and effective pattern matching expressions.
Why is \\ used in regex?
In regex, the double backslash (\\) is used as an escape character to indicate that the following character should be treated as a literal character rather than a special regex metacharacter. This is necessary because certain characters have special meanings in regex, such as the dot (.) representing any single character and the asterisk (*) indicating zero or more occurrences. By using the double backslash before a special character, we are essentially telling the regex engine to interpret it as a regular character to be matched in the text. This practice helps avoid confusion and ensures that specific characters are matched based on their literal representation rather than their regex functionality.
What is the R in regex?
The “R” in regex stands for “regular expression.” Regular expressions are sequences of characters that define a search pattern, allowing users to match and manipulate text based on specific rules or patterns. In the context of programming and data processing, regular expressions are powerful tools for searching, extracting, and replacing text within strings. The “R” in regex signifies the foundational concept of regularity in defining patterns within text data, enabling users to perform complex text-processing operations efficiently and effectively.